
Aquatone is one of my favorite tools for performing recon against a wide range of web servers and it's goal is to capture screenshots of the applications running on the web servers, categorize them based on similarity, and output a visual report. Compared to tools such as eyewitness, aquatones clustering feature makes it the tool of choice when attempting to identify applications across a wide range of assets.
I'm going to detail some features I've added to aquatone throughout this post and provide an example of my improvements to the initial session feature.
Similarity Option
I've added a quick option to actually change the similarity ratio inside of aquatone. By default, aquatone attempts to categorize applications based on 80% similarity, which has been hardcoded. This option will allow any perfect float value to be used as an argument for additional correlation, this is especially helpful as you can now rerun reports easily if the applications are not mapped to your liking.
InputFile Option
Additionally, I've added another option to parse input into aquatone from a file: either an nmap scan or a raw file containing a list of hosts/urls. In a prior version of aquatone, this feature was there, however with the rewrite in golang the choice was made to parse standard input. I have some other tools that really depend on reading from a file when chaining together tools, so a quick fix here allows input from a file. I've created a pull request with the aquatone project for these two features.
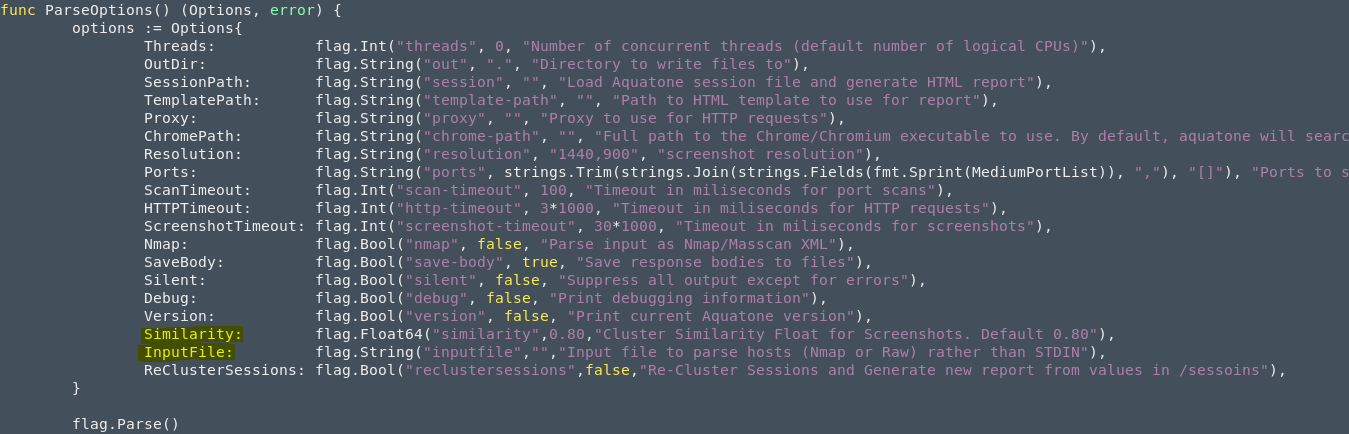
ReClusterSessions Option
Lastly, the most interesting feature I've added into the aquatone project is the ability to recluster already 'aquatoned' assets. Previously, if you wanted to scan multiple lists of hosts (perhaps days apart, or splitting up scanning based on subnets) you would be forced to have individual aquatone folders containing all the screenshots/headers/responses inside of them with a single report for each of your split out groups. This is not ideal, as you cannot go back and regroup similar web applications across these groups of files.
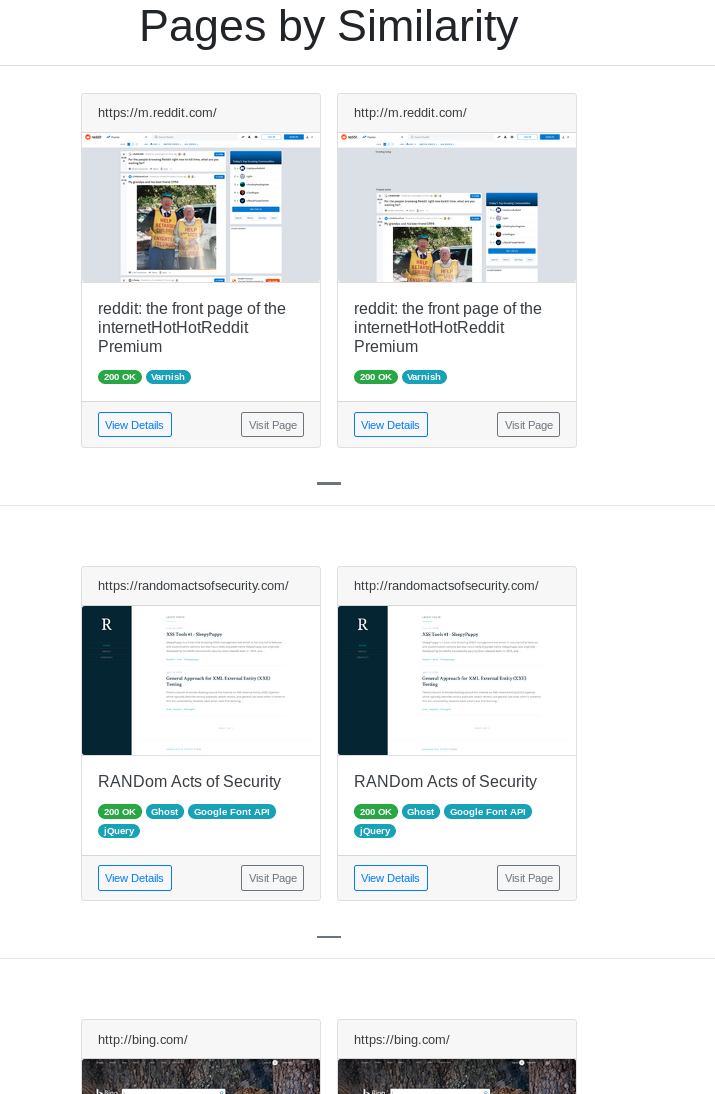
For example, we have the following hosts file containing three websites along with the corresponding aquatone report splitting these assets into their unique buckets.

Next, we have a second hosts file containing three additional websites along with the corresponding report.
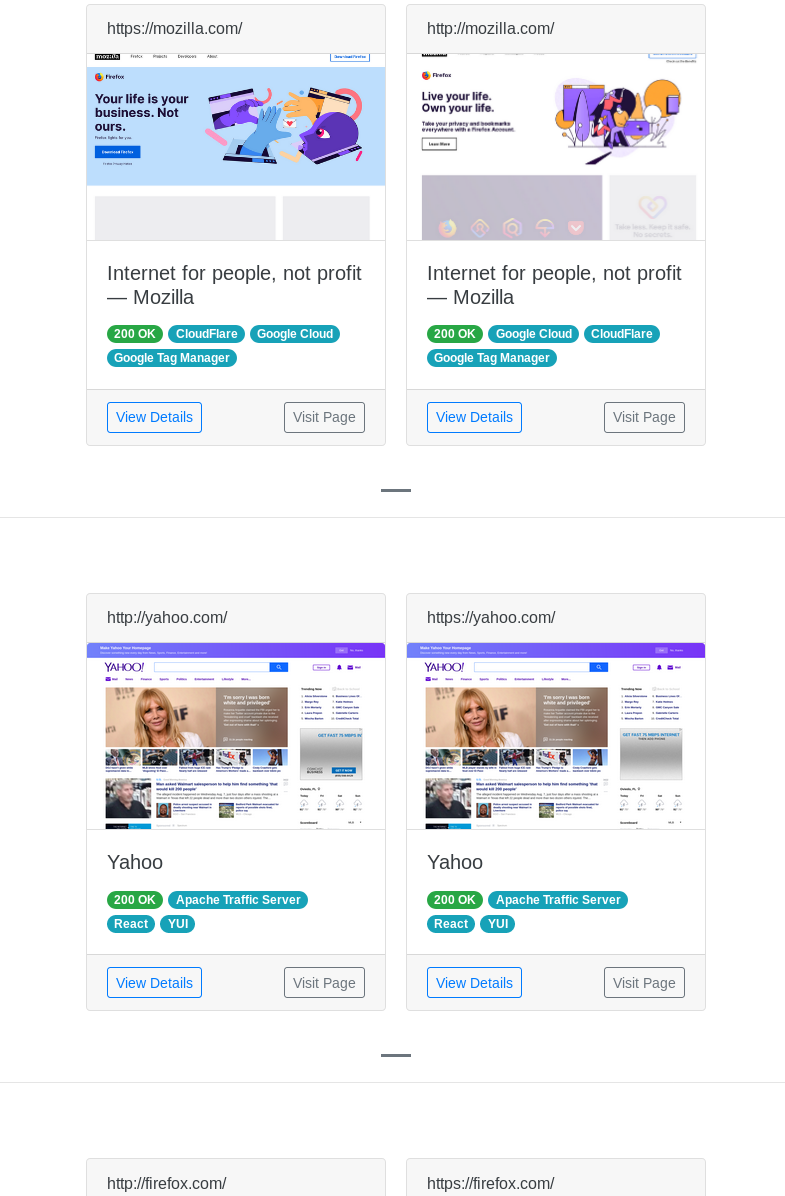
In the current state of aquatone, that's the structure you will have to unfortunately cope with. However, I have added a feature to fix this which works fairly well. I've changed aquatone to output the 'sessions.json' into individual unique sub directories, and then parse all of those sessions and recluster them to create a new report.
Working off our example above, we now have each scan inside their own sessions folder containing the json files.
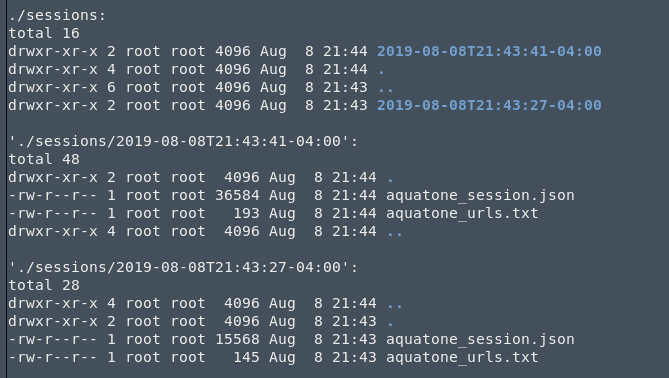
Now all we have to do is recluster those sessions and we get a freshly merged aquatone html report.

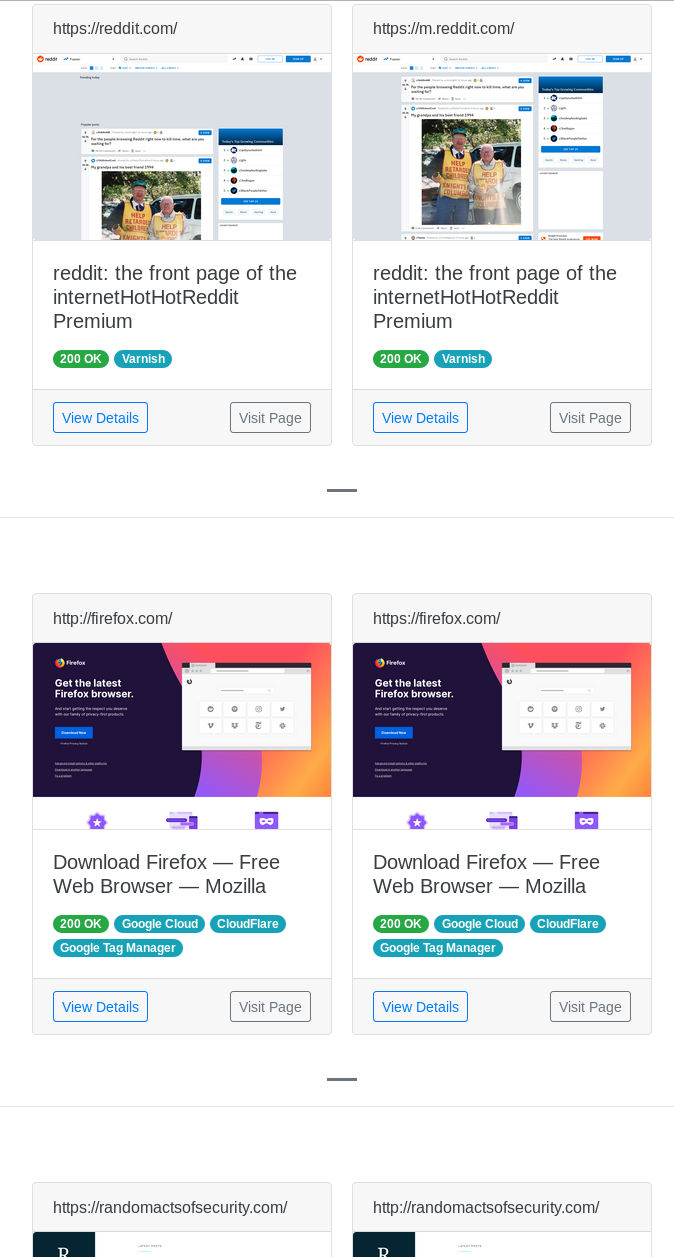
You can grab the code for this option here, I will not be attempting to merge this into the aquatone source as it's not in the best state at the moment, and messes with the overall structure of the aquatone output that I'm not sure follows the authors direction.
Just writing this blog post so I can remember the purpose of this code in the future when I need to do more recon again.
In the future, I want to dive into the actual clustering ratio and see if we can improve upon the current categorization of web applications in aquatone. For now, I'll continue to learn golang and add some more quality of life improvements to aquatone :)